Introduction to WEKA
WEKA (Waikato Environment for Knowledge Analysis) implements learning algorithms that can be easily applied to the dataset. Currently, the latest stable version is Weka 3.8, and the development version is Weka 3.9. The download link for both versions is here.

References
And here are some references:

Public Dataset: UCI ML Repository
Actually, WEKA already provided the datasets in the folder <data>. Still, popular public datasets, such as UCI ML Repository, can also be used to find the various datasets, either in the old or the new/beta versions.

The Package Management System
Besides the default algorithm already installed in <the explorer>, WEKA also has the feature “package manager,” which can be used to search and install the other algorithms.

Simple Example
The first step, choose the <open file> from <the explorer>, as shown in Figure 5.

The second step is preparing the data. For example, choose <weather.numeric> from the folder <data>. WEKA uses the .arff as the default data format but can also read the .csv file.

After loading the weather data into <the explorer>, the visualization for the dataset can be seen in Figure 8.

WEKA also provides an unbalanced dataset as the sample dataset, as seen in Figure 9.

The third step is to build the model. For example, the CART (classification and regression tree) algorithm can classify the weather dataset. Figure 10 shows the classifier output: accuracy and confusion matrix.
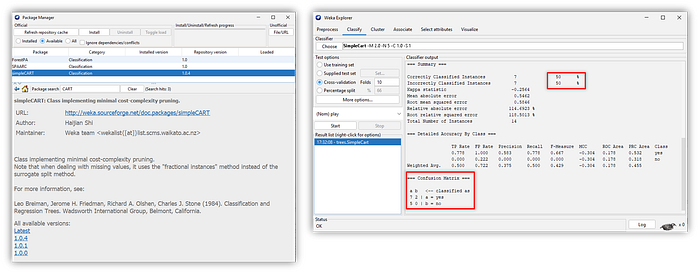
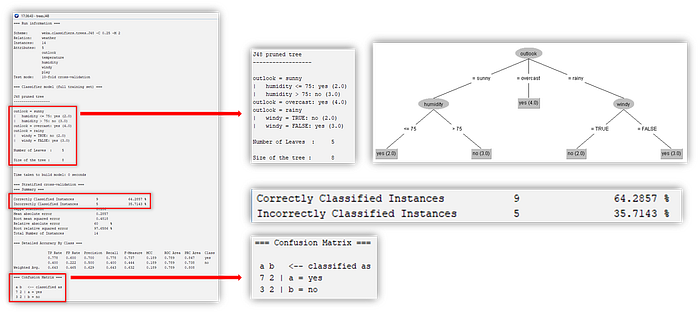
Another method to build a decision tree is using the J48 algorithm. This algorithm is the improved version of the C45 algorithm. As a result, as shown in Figure 11, the J48 algorithm has better accuracy than the CART algorithm, which is 64.29%.
Thank you. Hopefully, this article can provide a simple explanation of how to get started with WEKA.
